
فایل robots.txt چیست. برچسب های روبات متا (meta robots) ابزاری اساسی برای بهبود رفتار خزنده و نمایهسازی موتور جستجو و کنترل قطعههای خود در SERP است. اما meta robots چیست. Robots txt میتواند بسیاری از صفحات را برای خزیدن در یک وبسایت مسدود کند این مقاله آموزشی راهنمایی خواهد کرد که چگونه میتوانید از Robots.TXT و ROBOTS META TAG استفاده کنید تا بهترین نتایج سئو سایت را بگیرید. در این مقاله به شما خواهیم گفت فایل robots.txt چیست و در ادامه با دلایل استفاده، نحوه کار، دستورات مهم و نحوه بهینهکردن آن آشنا خواهیم شد.
متا تگ روبات چیست؟ اهمیت آن را بشناسید!

برچسب یا متا تگ Meta Robots این امکان را به صاحبان سایت میدهد که بر رفتار خزنده و نمایه سازی موتورهای جستجو و نحوه ارائه سایت های آنها در صفحات نتیجه موتور جستجو (SERP) نظارت داشته باشند.
برچسب Meta Robots یکی از برچسب های متا است که در بخش HTML شما قرار دارد. مسلماً مشهورترین برچسب روبات های متا ، همانی است که به موتورهای جستجوگر میگوید یک صفحه را فهرست بندی نکنند:
شما میتوانید با استفاده از آنها در هدر HTTP با استفاده از برچسب X-Robots ، دستورالعمل های لازم را به ربات های گوگل جهت ایندکس نمودن صفحات وب خود ارائه دهید. همچنین از برچسب X-Robots اغلب برای جلوگیری از فهرست بندی های غیر HTML مانند PDF و تصاویر استفاده میشود.
از نظر سئو سایت، اگر میخواهید گوگل را از خزیدن یک صفحه خاص در وب سایت خود و فهرست کردن آن در صفحات نتایج جستجوی خود مسدود کنید، بهتر است از تگ متا روبات استفاده کنید تا به آنها بگویید که اجازه دسترسی به این صفحه را دارند اما آن را در SERPها نشان ندهد.
ما در این قسمت به سئو اشاره کردیم اما اگر راجع به آن اطلاعات ندارید و نمی دانید سئو چیست، پیشنهاد میکنیم برای درک بهتر ادامه مطلب، مقاله هایی حول آن مطالعه فرمایید.
متا تگ روبات شما باید به شکل زیر باشد و در قسمت وب سایت شما قرار گیرد:
اگر میخواهید خزنده را از ایندکس کردن محتوا در صفحه خود منع کنید و از دنبال کردن هر یک از پیوندها جلوگیری کنید، تگ متا روبات شما به این صورت خواهد بود:
نمای کلی از دستورات تگ متا روبات اصلی به شرح زیر است:
- Index: همه موتورهای جستجو میتوانند محتوای این صفحه وب را فهرست کنند.
- Follow: همه موتورهای جستجو میتوانند از طریق پیوندهای داخلی در صفحه وب بخزند.
- Noindex: از قرار گرفتن صفحه تعیین شده در فهرست جلوگیری میکند.
- Nofollow: مانع از دنبال کردن رباتهای Google از پیوندهای موجود در صفحه میشود. توجه داشته باشید که این با ویژگی پیوند rel=”nofollow” متفاوت است.
- Noarchive: از نمایش نسخه های کش شده صفحه در SERPها جلوگیری میکند.
- Nosnippet: از کش شدن صفحه و نمایش توضیحات در زیر صفحه در SERPها جلوگیری میکند.
- NOODP: از توضیح پروژه دایرکتوری باز برای صفحه جلوگیری میکند و به جای توضیحات تنظیم شده دستی برای این صفحه
- Noimageindex: از ایندکس شدن تصاویر در صفحه توسط گوگل جلوگیری میکند
- Notranslate: از ترجمه صفحه در SERP های گوگل جلوگیری میکند
میتوانید از چندین دستور در تگ متا روبات خود استفاده کنید. اگر میخواهید از کش شدن یک صفحه در وب سایت خود توسط همه موتورهای جستجو جلوگیری کنید و همچنین از جایگزینی توضیحات Open Directory به جای توضیحات فعلی شما جلوگیری کنید، از دستورات زیر استفاده میکنید: noarchive و NOODP.
پيشنهاد سیتی سایت: cannibalization چیست
فایل robots.txt چیست؟
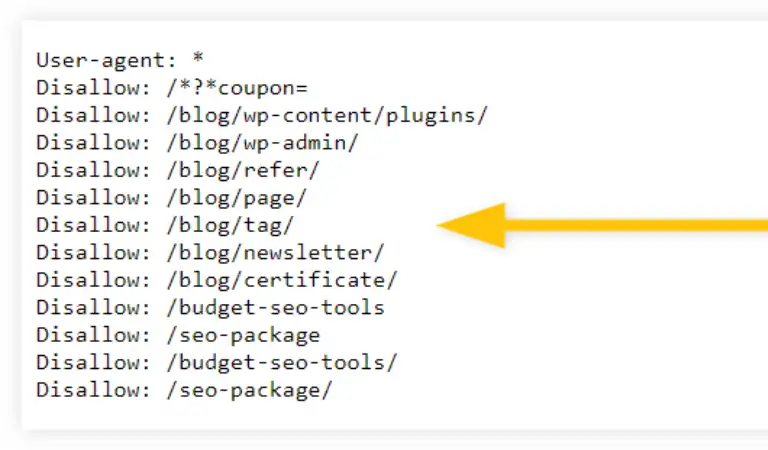
یک فایل robots.txt در ریشه سایت شما قرار دارد. بنابراین، برای سایت www.example.com، فایل robots.txt در www.example.com/robots.txt قرار دارد. robots.txt یک فایل متنی ساده است که از استاندارد حذف روباتها پیروی میکند. یک فایل robots.txt از یک یا چند قانون تشکیل شده است.
هر قانون دسترسی همه یا یک خزنده خاص را به مسیر فایل مشخص شده در دامنه یا زیر دامنه ای که فایل robots.txt در آن میزبانی میشود مسدود میکند یا اجازه میدهد. مگر اینکه چیز دیگری در فایل robots.txt خود مشخص کنید، همه فایلها به طور ضمنی برای خزیدن مجاز هستند.
فایل robots.txt یک سند متنی با کد UTF-8 است که برای http، https و همچنین پروتکلهای FTP معتبر است. این فایل توصیه هایی را برای ربات های موتور جستجو ارائه میدهد که در کدام صفحات یا فایلها باید خزیده شوند. اگر یک فایل حاوی نویسههایی باشد که با UTF-8 کدگذاری شدهاند، خزندههای جستجو ممکن است آنها را اشتباه پردازش کنند. دستورالعملهای فایل robots.txt فقط با میزبان، پروتکل و شماره پورتی که فایل در آن قرار دارد کار میکند.
پيشنهاد سیتی سایت: ریدایرکت چیست
چرا فایل Robots.txt مهم است؟
۱- مدیریت ترافیک رباتها
فایل robots.txt به چند دلیل مختلف بخش ضروری هر وب سایتی است. اولین و واضح ترین آنها این است که آنها شما را قادر میسازند کنترل کنید که کدام صفحات در سایت شما خزیده شوند و کدام صفحات خزیده نشوند.
این را میتوان با دستور “اجازه” یا “عدم اجازه” انجام داد. در بیشتر موارد، شما از دومیبیشتر از اولی استفاده خواهید کرد، در حالی که دستور allow واقعاً فقط برای بازنویسی غیر مجاز مفید است. غیر مجاز کردن صفحات خاص به این معنی است که خزندهها هنگام خواندن وب سایت شما، آنها را حذف میکنند.
۲- جلوگیری از نمایش برخی از صفحات یا فایلها در گوگل
ممکن است تعجب کنید که چرا میخواهید این کار را انجام دهید. آیا هدف اصلی سئو و سئو تصاویر این نیست که موتورهای جستجو و در نتیجه کاربران بتوانند صفحات شما را آسان تر پیدا کنند؟
بله و خیر. در واقع، تمام هدف سئو این است که موتورهای جستجو و کاربران آنها را راحتتر پیدا کنند تا صفحات صحیح را پیدا کنند. تقریباً هر وبسایتی، مهم نیست که چقدر بزرگ یا کوچک باشد، صفحاتی دارد که برای کسی جز شما دیده نمیشود. اجازه دادن به خزندهها برای خواندن این صفحات، احتمال نمایش آنها در نتایج جستجو را به جای صفحاتی که واقعاً میخواهید کاربران بازدید کنند، افزایش میدهد.
نمونههایی از صفحاتی که ممکن است بخواهید خزیدن را ممنوع کنید شامل موارد زیر است:
- صفحات با محتوای تکراری
- صفحاتی که هنوز در حال ساخت هستند
- صفحاتی که قرار است منحصراً از طریق URL یا ورود به سیستم قابل دسترسی باشند
- صفحاتی که برای کارهای اداری استفاده میشوند
- صفحاتی که در واقع فقط منابع چندرسانه ای هستند (مانند تصاویر یا فایل های PDF)
از آنجایی که گوگل و سایر موتورهای جستجو فقط میتوانند صفحات زیادی را در یک وب سایت بخزند، مهم است که مطمئن شوید که مهمترین صفحات شما (یعنی صفحاتی که باعث ایجاد ترافیک، اشتراک گذاری و تبدیل میشوند) نسبت به موارد کم اهمیت اولویت دارند.
۳- مدیریت Crawl Budget (بودجه خزش)

برای وبسایتهای بزرگ با صدها یا حتی هزاران صفحه (به عنوان مثال، وبلاگها یا سایتهای تجارت الکترونیک)، عدم مجوز به برخی صفحات سایت میتواند به شما کمک کند از هدر دادن «بودجه خزیدن» خود جلوگیری کنید.
بیشتر اوقات، شما به همه خزندهها از یک صفحه یا صفحات خاص اجازه یا غیرمجاز میدهید. با این حال، ممکن است مواردی وجود داشته باشد که بخواهید به جای آن خزندههای خاصی را هدف قرار دهید.
به عنوان مثال، اگر میخواهید سرقت تصویر یا سوء استفاده از پهنای باند را کاهش دهید، بهجای اینکه فهرست گستردهای از URLهای منابع رسانهای را غیرقانونی کنید، منطقیتر است که Googlebot-Image و سایر خزندههای تصویر محور را غیرفعال کنید.
زمان دیگری که ممکن است بخواهید خزندههای خاصی را غیرمجاز کنید، این است که ترافیک مشکل دار یا هرزنامه زیادی را از یک موتور جستجو بیشتر از موتور جستجوی دیگر دریافت میکنید.
ترافیک هرزنامه از رباتها و سایر منابع به احتمال زیاد به وب سایت شما آسیب نمیرساند (اگرچه میتواند به بارگذاری بیش از حد سرور کمک کند، موضوعی که کمیبعداً در مورد آن صحبت خواهیم کرد). با این حال، میتواند تجزیه و تحلیل شما را به طور جدی منحرف کند و توانایی شما را برای تصمیم گیری دقیق و مبتنی بر دادهها مهار کند.
پيشنهاد سیتی سایت: تگ Canonical چیست
چرا باید robots.txt داشته باشیم؟

چه یک وب سایت کوچک باشد یا یک وب سایت بزرگ داشته باشید، داشتن یک فایل robots.txt بسیار مهم است. این فایل به شما کنترل بیشتری بر حرکت موتورهای جستجو در وب سایت شما میدهد. در حالی که یک دستورالعمل غیرمجاز تصادفی میتواند باعث خزیدن Googlebot در کل سایت شما شود، موارد رایجی وجود دارد که واقعاً میتواند مفید باشد.
robots.txt از نقطه نظر تکنیکال سئو نقش اساسی دارد. به موتورهای جستجو میگوید که چگونه میتوانند وب سایت شما را به بهترین نحو بخزند.
با استفاده از فایل robots.txt میتوانید از دسترسی موتورهای جستجو به بخشهای خاصی از وبسایت خود جلوگیری کنید، از محتوای تکراری جلوگیری کنید و به موتورهای جستجو راهنماییهای مفیدی در مورد اینکه چگونه میتوانند وبسایت شما را به طور مؤثرتر خزیدن کنند، ارائه دهید.
با این حال، هنگام ایجاد تغییرات در robots.txt خود مراقب باشید: این فایل این پتانسیل را دارد که بخشهای بزرگی از وبسایت شما را برای موتورهای جستجو غیرقابل دسترس کند.
ما در این قسمت به سئو اشاره کردیم اما اگر راجع به مراحل انجام سئو اطلاعات ندارید، پیشنهاد میکنیم برای درک بهتر ادامه مطلب، مقاله هایی حول آن مطالعه فرمایید.
۱- در مواقعی که محتوای تکراری روی سایت داشته باشید، یکی از صفحات را disallow کنید.
محتوای تکراری گوگل را گیج میکند و موتور جستجو را مجبور میکند انتخاب کند که کدام یک از صفحات یکسان را در نتایج برتر قرار دهد. صرف نظر از اینکه چه کسی محتوا را تولید کرده است، احتمال زیادی وجود دارد که صفحه اصلی برای بهترین نتایج جستجو انتخاب نشده باشد.
ما میدانیم که محتوای تکراری برای سئو و تبلیغات گوگل مضر است و اگر یک وب سایت دارای محتوای تکراری باشد، ممکن است به رتبه بندی آن آسیب وارد شود. با این حال، گاهی اوقات سایتها به قدری بزرگ هستند که شناسایی و حذف/حل هر نمونه از محتوای تکراری در سراسر سایت اغلب کار دشواری است.
در حالی که استفاده از تگ های Canonical اغلب میتواند به نتایج دلخواه برسد، گاهی اوقات ممکن است (به ویژه برای سایت های بزرگ) پیاده سازی آن به عنوان یک راه حل در سطح سایت دشوار باشد. اغلب، مسدود کردن صفحات یا دایرکتوریهای خاصی که نیازی به رتبهبندی آنها از خزیدن توسط موتورهای جستجو با استفاده از فایل robots.txt نیست، سریعتر و آسانتر است.
پيشنهاد سیتی سایت: Google tag manager چیست
۲- بخشی از سایت را در دسترس عموم قرار ندهید.
لازم نیست به موتورهای جستجو اجازه دهید هر صفحه در سایت شما را بخزند زیرا همه آنها نیازی به رتبه بندی ندارند. به عنوان مثال میتوان به سایت های مرحله بندی، صفحات نتایج جستجوی داخلی، صفحات تکراری یا صفحات ورود اشاره کرد.
به عنوان مثال، وردپرس به طور خودکار /wp-admin/ را برای همه خزندهها غیرمجاز میکند. این صفحات باید وجود داشته باشند، اما شما نیازی به ایندکس شدن و یافتن آنها در موتورهای جستجو ندارید. یا برای احتناب از پنالتی گوگل نیازی نیست صفحه ای ایندکس شود. یک مورد عالی که در آن از robots.txt برای مسدود کردن این صفحات از خزندهها و رباتها استفاده میکنید.
۳- مکان نقشه سایت را برای رباتهای گوگل مشخص کنید.
نقشه سایت XML یک فایل xml. است که تمام صفحات یک وبسایت را فهرست میکند که میخواهید فایل Robots.txt آنها را پیدا کرده و به آنها دسترسی داشته باشد.
به عنوان مثال، اگر یک وب سایت تجارت الکترونیک با وبلاگی دارید که موضوعات مختلفی را در صنعت شما پوشش میدهد، باید زیرپوشه وبلاگ را به نقشه سایت XML اضافه کنید تا خزندهها به این صفحات دسترسی داشته باشند و در SERPها رتبه بندی کنند.
اما شما باید صفحات فروشگاه، سبد خرید و پرداخت را در نقشه سایت XML کنار بگذارید، زیرا این صفحات فرود خوبی برای بازدید مشتریان بالقوه نیستند. مشتریان شما به طور طبیعی هنگام خرید یکی از محصولات شما از این صفحات عبور میکنند، اما مطمئناً برای مثال، سفر تبدیل خود را در صفحه پرداخت شروع نمیکنند.
نقشه های سایت XML همچنین اطلاعات مهمی را در مورد هر URL از طریق متا داده های آن حمل میکنند. این برای SEO (بهینه سازی موتور جستجو) مهم است زیرا متا دادهها نظیر انکرتکست حاوی اطلاعات مهم رتبه بندی هستند که به URLها اجازه میدهد در SERPها در برابر رقبا رتبه بندی کنند. بهتر است مکان نقشه سایت را به پایین فایل robots.txt اضافه کنید.
پيشنهاد سیتی سایت: راهنمای کامل تحقیق کلمات کلیدی برای سئو
۴- اجازه ندهید رباتها برخی فایلهای روی سایتتان را ایندکس کنند.
گاهی اوقات میخواهید Google منابعی مانند PDF، ویدیوها و تصاویر را از نتایج جستجو حذف کند. شاید بخواهید آن منابع را خصوصی نگه دارید یا تمرکز گوگل را روی محتوای مهم تری برای افزایش رتبه سئو ویدیو قرار دهید. در این صورت، استفاده از robots.txt بهترین راه برای جلوگیری از ایندکس شدن آنهاست و باعث کاهش سئو کلاه سیاه میشود.
ما در این قسمت به سئو اشاره کردیم راجع به بهترین افزونه سئو وردپرس، پیشنهاد میکنیم برای درک بهتر ادامه مطلب، مقاله هایی حول آن مطالعه فرمایید.
۵- برای رباتها یک زمان تأخیر در خزیدن تعریف کنید تا وقتی سایت شلوغ میشود، سرعت پایین نیاید.
با گنجاندن فرمان «تاخیر خزیدن» در robots.txt خود، میتوانید نه تنها صفحاتی را که خزندهها میخوانند، بلکه سرعت انجام آن را کنترل کنید. به طور معمول، خزندههای موتورهای جستجو بسیار سریع هستند و از صفحه به صفحه به صفحه به صفحه دیگر بسیار سریعتر از هر انسانی میچرخند که آنها را بسیار قدرتمند و کارآمد میکند.
هر چه یک وب سایت ترافیک بیشتری دریافت کند، سروری که روی آن میزبانی میشود باید برای نمایش صفحات سایت سخت تر کار کند. زمانی که میزان ترافیک از توانایی سرور برای تطبیق با آن فراتر رود، نتیجه اضافه بار است. این بدان معنی است که سرعت صفحه تا خزیدن کاهش مییابد و همچنین خطاهای 500، 502، 503 و 504 افزایش مییابد و رتبه سئو خارجی و داخلی کاهش مییابد. به زبان ساده یعنی فاجعه.
اگرچه اغلب این اتفاق نمیافتد، خزندههای موتورهای جستجو میتوانند با عبور از ترافیک از نقطه اوج، به اضافه بار سرور کمک کنند. اگر این چیزی است که شما نگران آن هستید، میتوانید به خزندهها دستور دهید تا سرعت خود را کاهش دهند و حرکت آنها به صفحه بعدی را بین 1 تا 30 ثانیه به تاخیر بیندازید.
پيشنهاد سیتی سایت: AMP چیست
آشنایی با دستورات فایل Robots.txt
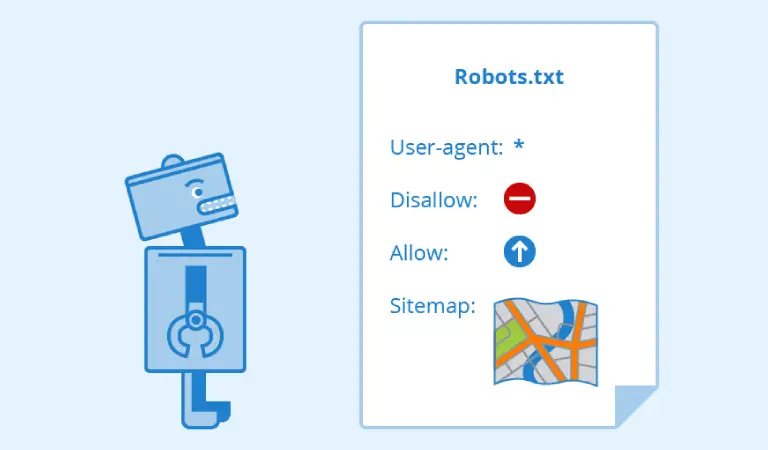
دستور اول: User-agent
به یک ربات خاص اشاره میکند که به آن دستورالعمل های خزیدن (به عنوان مثال موتور جستجو) را میدهید. هر موتور جستجو باید خود را با یک عامل کاربر شناسایی کند. ربات های گوگل به عنوان مثال Googlebot، ربات های یاهو به عنوان Slurp و ربات Bing به عنوان BingBot و غیره شناخته میشوند.
رکورد عامل کاربر شروع گروهی از دستورالعملها را تعریف میکند. همه دستورات بین اولین کاربر عامل و رکورد بعدی عامل کاربر به عنوان دستورالعمل برای اولین عامل کاربر تلقی میشوند.
دستورالعملها میتوانند در مورد عوامل کاربر خاص اعمال شوند، اما میتوانند برای همه عوامل کاربر نیز قابل اجرا باشند. در آن صورت، یک علامت عام استفاده میشود: User-agent: *.
دستور دوم: Disallow
دستوری است که به ربات میگوید یک URL خاص را نخزد. میتوانید به موتورهای جستجو بگویید که به فایل ها، صفحات یا بخش های خاصی از وب سایت شما دسترسی نداشته باشند. این کار با استفاده از دستور Disallow انجام میشود. دستورالعمل Disallow مسیری را دنبال میکند که نباید به آن دسترسی داشت. اگر مسیری تعریف نشده باشد، دستورالعمل نادیده گرفته میشود.
مثال:
User-agent: *
Disallow: /wp-admin/
در این مثال به همه موتورهای جستجو گفته میشود که به دایرکتوری wp-admin/ دسترسی نداشته باشند.
دستور سوم: Allow
دستوری است که به ربات میگوید یک URL خاص را بخزد، حتی در یک فهرست غیر مجاز. دستور Allow برای مقابله با دستورالعمل Disallow استفاده میشود. دستورالعمل Allow توسط Google و Bing پشتیبانی میشود.
با استفاده از دستورالعملهای Allow و Disallow میتوانید به موتورهای جستجو بگویید که میتوانند به یک فایل یا صفحه خاص در یک فهرست دسترسی داشته باشند که در غیر این صورت غیرمجاز است. دستورالعمل Allow مسیری را دنبال میکند که میتوان به آن دسترسی داشت. اگر مسیری تعریف نشده باشد، دستورالعمل نادیده گرفته میشود.
مثال:
User-agent: *
Allow: /media/terms-and-conditions.pdf
Disallow: /media/
در مثال بالا، همه موتورهای جستجو به جز فایل /media/terms-and-conditions.pdf اجازه دسترسی به فهرست media/ را ندارند.
تذکر مهم: هنگام استفاده از دستورالعملهای مجاز و غیر مجاز با هم، مطمئن شوید که از حروف عام استفاده نکنید زیرا ممکن است منجر به دستورالعملهای متناقض شود.
مثال:
User-agent: *
Allow: /directory
Disallow: *.html
در مثال بالا موتورهای جستجو نمیدانند با URL http://www.domain.com/directory.html چه کنند. برای آنها مشخص نیست که آیا آنها اجازه دسترسی دارند یا خیر. وقتی دستورالعملها برای Google واضح نباشند، با کمترین دستورالعملهای محدودکننده پیش میروند، که در این مورد به این معنی است که آنها در واقع به http://www.domain.com/directory.html دسترسی خواهند داشت.
دستور چهارم: Sitemap
به تعیین مکان نقشه (های) سایت برای ربات کمک میکند. بهترین روش برای این کار قرار دادن دستورالعمل های نقشه سایت در انتهای یا ابتدای فایل robots.txt است. همچنین فایل robots.txt میتواند برای نشان دادن موتورهای جستجو به نقشه سایت XML استفاده شود. این توسط Google، Bing، Yahoo و Ask پشتیبانی میشود.
نقشه سایت XML باید به عنوان یک URL مطلق ارجاع داده شود. لزومیندارد که URL در همان میزبان فایل robots.txt باشد.
ارجاع به نقشه سایت XML در فایل robots.txt یکی از بهترین روش هایی است که به شما توصیه میکنیم همیشه انجام دهید، حتی اگر قبلاً نقشه سایت XML خود را در کنسول جستجوی گوگل یا ابزار وب مستر بینگ ارسال کرده باشید. به یاد داشته باشید، موتورهای جستجوی بیشتری وجود دارد.
لطفاً توجه داشته باشید که میتوان به چندین نقشه سایت XML در یک فایل robots.txt اشاره کرد.
مثال:
چندین نقشه سایت XML تعریف شده در فایل robots.txt:
User-agent: * Disallow: /wp-admin/ Sitemap: https://www.example.com/sitemap1.xml Sitemap: https://www.example.com/sitemap2.xml
مثال بالا به همه موتورهای جستجو میگوید که به دایرکتوری /wp-admin/ دسترسی نداشته باشند و دو نقشه سایت XML وجود دارد که میتوانید آنها را در https://www.example.com/sitemap1.xml و https://www.exampl.com/sitemap2.xml
پيشنهاد سیتی سایت: اشتباهات فاحش در سئو
محدودیتهای دستورات Robots.txt

عکس از سایت Yoast.com
۱- دستورات استفاده شده در فایل Robots.txt برای همه رباتهای موتورهای جستجو یکسان نیست.
دستورالعملهای موجود در فایلهای robots.txt نمیتوانند رفتار خزنده را در سایت شما و لندینگ پیج کنترل کنند. در حالی که Googlebot و سایر خزندههای وب معتبر از دستورالعملهای فایل robots.txt پیروی میکنند، خزندههای دیگر ممکن است این کار را نکنند.
بنابراین، اگر میخواهید اطلاعات را از خزندههای وب ایمن نگه دارید، بهتر است از سایر روشهای مسدود کردن مانند محافظت از فایلهای خصوصی با رمز عبور روی سرور خود استفاده کنید.
۲- امکان دارد هر کدام از رباتها دستورات را به شکل متفاوتی درک کند.
اگرچه خزندههای وب محترم از قوانین موجود در فایل robots.txt پیروی میکنند، اما هر خزنده ممکن است قوانین را متفاوت تفسیر کند. شما باید نحو مناسب برای آدرس دادن به خزنده های وب مختلف را بدانید زیرا ممکن است برخی دستورالعمل های خاصی را درک نکنند.
۳- اگر اجازه بررسی صفحهای را با دستورات فایل ربات نداده باشیم باز هم امکان دارد گوگل آن را ایندکس کند.
در حالی که Google محتوای مسدود شده توسط یک فایل robots.txt را نمیخزد یا فهرستبندی نمیکند، اما اگر از مکانهای دیگر در وب پیوند داده شده باشد، ممکن است URL غیرمجاز را توسط بک لینک PBN پیدا کرده و فهرستبندی کند.
در نتیجه، آدرس URL و احتمالاً سایر اطلاعات عمومیدر دسترس مانند متن لنگر در پیوندهای صفحه همچنان میتوانند در نتایج جستجوی Google ظاهر شوند. برای جلوگیری از نمایش صحیح URL خود در نتایج جستجوی Google، از فایل های سرور خود با رمز عبور محافظت کنید، از متا تگ noindex یا سرصفحه پاسخ استفاده کنید یا صفحه را به طور کامل حذف کنید.
پيشنهاد سیتی سایت: search intent چیست
فایل Robots.txt را از کجا پیدا کنیم؟
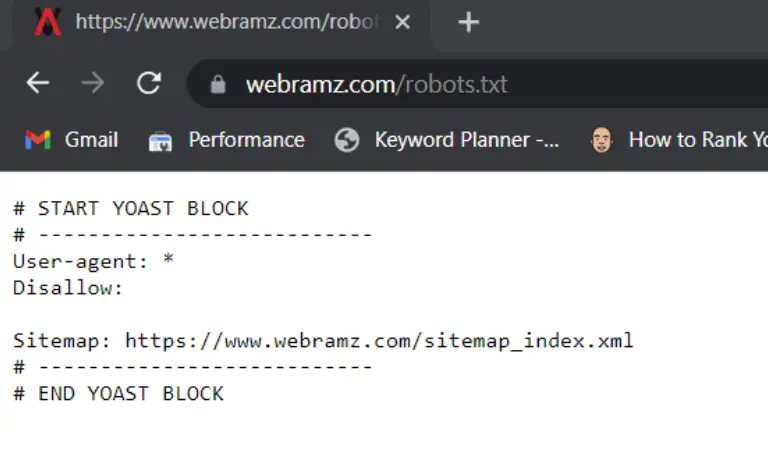
فایل he robots.txt مانند هر فایل دیگری در وب سایت شما، روی سرور شما میزبانی میشود. شما میتوانید فایل robots.txt را برای هر وب سایتی با تایپ URL کامل برای صفحه اصلی و سپس اضافه کردن /robots.txt مانند https://webramz.com/robots.txt مشاهده کنید.
ساخت و بارگذاری فایل robots
اگر از قبل فایل robots.txt ندارید، ایجاد آن آسان است. میتوانید از یک ابزار مولد robots.txt استفاده کنید، یا میتوانید خودتان آن را ایجاد کنید. در اینجا نحوه ایجاد یک فایل robots.txt تنها در چهار مرحله آورده شده است:
- یک فایل ایجاد کنید و نام آن را robots.txt بگذارید.
- قوانین را به فایل robots.txt اضافه کنید.
- فایل robots.txt را در سایت خود آپلود کنید.
فایل robots.txt را تست کنید. جهت این کار، بررسی کنید که آیا فایل robots.txt شما برای عموم قابل دسترسی است (یعنی آیا به درستی آپلود شده است). یک پنجره خصوصی در مرورگر خود باز کنید و فایل robots.txt خود را جستجو کنید. به عنوان مثال، https://webramz.com/robots.txt.
گوگل دو گزینه برای آزمایش نشانه گذاری robots.txt ارائه میدهد:
- آزمایشگر robots.txt در کنسول جستجو
- کتابخانه منبع باز robots.txt گوگل (پیشرفته)
پيشنهاد سیتی سایت: سئو منفی و راهکارهای مقابله با آن
نتیجه گیری
افزودن نقشه سایت خود در فایل robots.txt به ربات های موتور جستجو میگوید که نقشه سایت را کجا پیدا کنند و چگونه از آن برای خزیدن و ایندکس کردن سایت خود استفاده کنند. این قابلیت خزیدن سایت و سئو داخلی را بهبود میبخشد و منجر به نمایه سازی بهتر میشود.
به علاوه، زمانی که شما درکی واضح از ساختار و محتوای سایت خود در اختیار موتورهای جستجو قرار میدهید، نقشه سایت میتواند به بهبود رتبه بندی کلی شما در موتورهای جستجو کمک کند. جهت کسب اطلاعات بیشتر میتوانید با متخصصین سیتی سایت تماس حاصل نمایید.

